Por qué el mercado está pasando de chip de entrenamiento a los de inferencia






La demanda migra de chips para entrenamiento hacia chips optimizados para inferencia, es decir, la ejecución diaria de modelos de IA en aplicaciones reales. La inferencia ya concentra el mayor volumen de cómputo de la industria, impulsada por chatbots, copilotos y agentes de IA que operan en tiempo real. El negocio deja de medirse por potencia bruta y pasa a medirse por costo por consulta, latencia y eficiencia energética.
Durante los primeros años del boom de la Inteligencia Artificial generativa, la carrera tecnológica se concentró en un objetivo muy específico: entrenar modelos cada vez más grandes. Empresas tecnológicas y startups invirtieron miles de millones de dólares en centros de datos equipados con GPU capaces de procesar volúmenes gigantescos de datos para construir sistemas como GPT, Gemini o Claude.
Ese ciclo de inversión estuvo dominado por los chips de Nvidia, que se convirtieron en el estándar de facto para el entrenamiento de modelos de inteligencia IA. Sus procesadores gráficos de alto rendimiento permitieron realizar billones de operaciones matemáticas en paralelo, una capacidad esencial para entrenar redes neuronales de gran escala.
Sin embargo, el mercado de hardware para iInteligencia Artificial está entrando ahora en una nueva fase. La industria está experimentando un cambio estructural en la demanda de chips: el foco se desplaza desde el entrenamiento de modelos hacia su ejecución cotidiana en aplicaciones reales. Este cambio, que ya está redefiniendo las inversiones en centros de datos y el diseño de semiconductores, tiene implicancias directas para el negocio de la inteligencia artificial y para el futuro de la infraestructura digital.
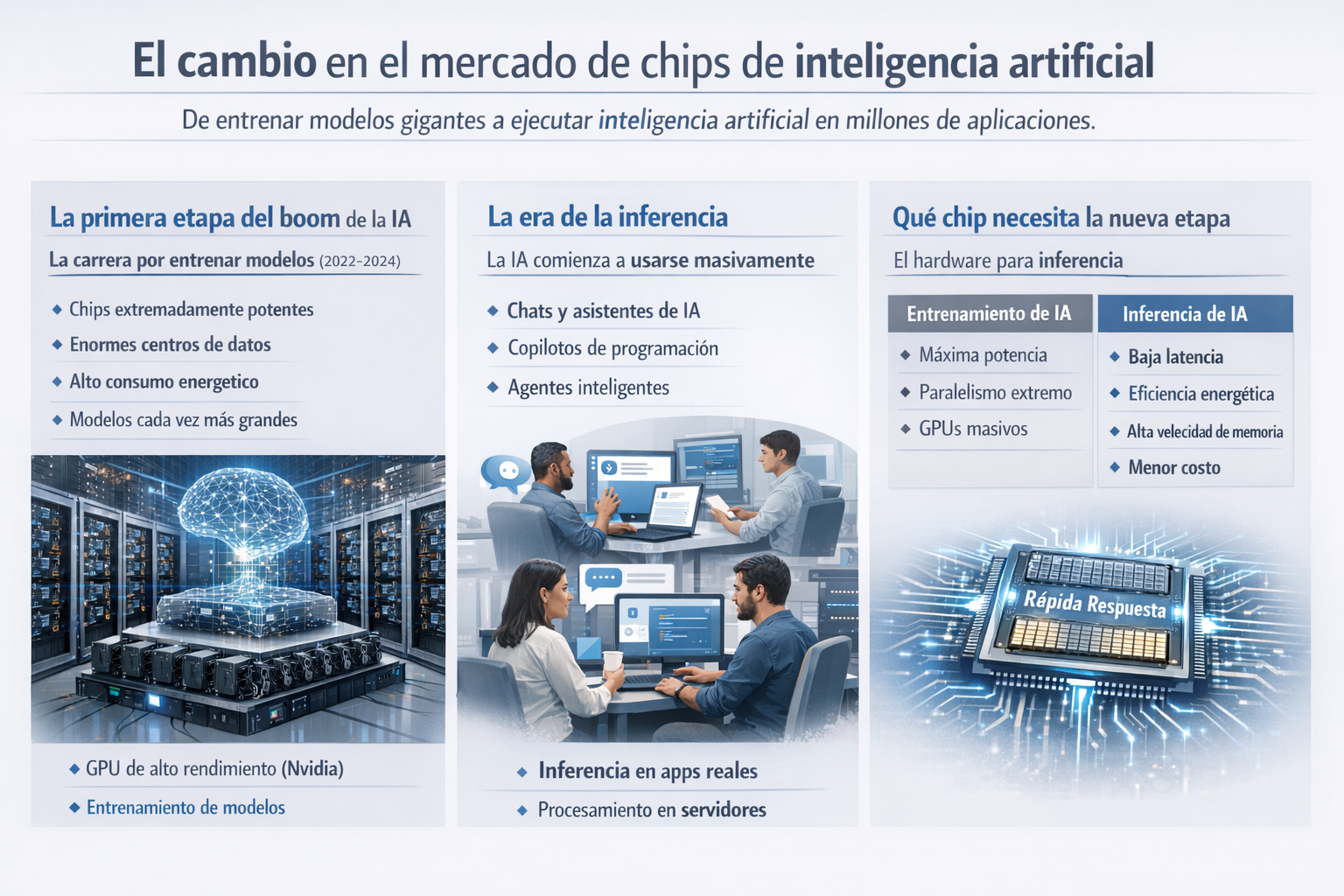
El entrenamiento de modelos es el proceso mediante el cual los sistemas de Inteligencia Artificial aprenden a partir de enormes bases de datos. Es una tarea intensiva en cómputo, pero ocurre relativamente pocas veces: una vez que un modelo está entrenado, puede ser utilizado durante meses o años.
La inferencia, en cambio, es el momento en que ese modelo se utiliza para responder preguntas o ejecutar tareas. Cada consulta a un chatbot, cada recomendación generada por un sistema de IA o cada interacción con un asistente digital implica ejecutar inferencia.
En la práctica, esto significa que mientras el entrenamiento ocurre ocasionalmente, la inferencia ocurre millones o incluso miles de millones de veces por día. Por esa razón, el volumen total de cómputo asociado a la inferencia está creciendo a un ritmo mucho más rápido que el entrenamiento. La industria tecnológica comienza a reconocer que el verdadero negocio de la inteligencia artificial no está solo en construir modelos, sino en ejecutarlos a escala global.
Este giro en el mercado responde a tres transformaciones centrales en el ecosistema de la IA. La primera es la expansión del uso de la IA en aplicaciones comerciales. Las empresas tecnológicas están incorporando modelos generativos en buscadores, software empresarial, herramientas de programación, asistentes digitales y sistemas de automatización. Cada una de esas aplicaciones genera miles de millones de consultas.
La segunda es la necesidad de reducir los costos de computación. El entrenamiento de modelos es extremadamente costoso, pero ocurre de manera esporádica. La inferencia, en cambio, debe ejecutarse constantemente, lo que obliga a optimizar cada operación para reducir el costo por respuesta.
La tercera es la aparición de los llamados agentes de Inteligencia Artificial. Estos sistemas no se limitan a responder preguntas, sino que pueden ejecutar tareas completas, coordinar flujos de trabajo y realizar múltiples consultas encadenadas. Ese tipo de uso multiplica el consumo de cómputo por usuario.
Como resultado, la industria está comenzando a demandar chips diseñados específicamente para ejecutar modelos de manera eficiente, con menor consumo energético y menor latencia.
La nueva arquitectura del hardware de IA
Los chips optimizados para inferencia tienen características distintas a los utilizados para entrenar modelos. Mientras que el entrenamiento requiere máxima potencia de cálculo y un alto grado de paralelismo, la inferencia prioriza eficiencia energética, velocidad de respuesta y acceso rápido a memoria.
Esto está impulsando el desarrollo de nuevas arquitecturas de semiconductores, incluyendo chips especializados diseñados exclusivamente para ejecutar modelos de inteligencia artificial.
Las grandes empresas tecnológicas ya están invirtiendo en sus propios procesadores para reducir su dependencia de proveedores externos. Google desarrolla sus unidades de procesamiento tensorial conocidas como TPU. Amazon diseñó los chips Trainium e Inferentia para sus centros de datos en la nube. Microsoft también está desarrollando procesadores específicos para inteligencia artificial.
Este movimiento refleja una tendencia clara: las grandes plataformas tecnológicas buscan controlar cada vez más la infraestructura que ejecuta sus sistemas de IA. Durante los primeros años del boom de la Inteligencia Artificial, Nvidia logró consolidar una posición dominante en el mercado de chips para centros de datos. Sus GPU se convirtieron en el componente central de la mayoría de las infraestructuras de entrenamiento de modelos.

Pero el cambio hacia la inferencia podría abrir la puerta a nuevos competidores. Además de las grandes tecnológicas que diseñan sus propios chips, una nueva generación de startups está desarrollando arquitecturas alternativas de computación para Inteligencia Artificial. Empresas como Cerebras o Groq buscan ofrecer procesadores especializados que ejecuten modelos con mayor eficiencia. Este nuevo escenario podría fragmentar el mercado de hardware de IA y reducir la dependencia de un único proveedor.
Las instalaciones diseñadas para Inteligencia Artificial requieren enormes cantidades de energía y sistemas avanzados de refrigeración. A medida que crece la demanda de inferencia, los centros de datos deberán optimizar la relación entre potencia de cálculo, consumo energético y costo operativo.
Esto podría impulsar nuevas estrategias de infraestructura, incluyendo el procesamiento distribuido y la ejecución de modelos directamente en dispositivos o redes locales.
Qué significa para los usuarios
Aunque el debate suele centrarse en semiconductores y centros de datos, el cambio en el hardware de IA tiene efectos directos sobre los usuarios finales. Los chips optimizados para inferencia permitirán que los sistemas de IA respondan con mayor rapidez y a menor costo. Esto facilitará la expansión de asistentes digitales, herramientas de productividad y aplicaciones basadas en IA.
También permitirá que más dispositivos ejecuten Inteligencia Artificial localmente, incluyendo computadoras personales, teléfonos móviles, vehículos y dispositivos conectados. En otras palabras, el cambio en el mercado de chips es un paso clave para que la IA deje de ser una tecnología experimental y se convierta en una infraestructura digital cotidiana.
La primera fase de la revolución de la IA estuvo marcada por la carrera por entrenar modelos cada vez más grandes. La segunda fase, que ya está en marcha, se define por un desafío diferente: ejecutar esos modelos de manera eficiente para millones de usuarios en todo el mundo.